
Here is a quick walk-through on how to use Azure Data Factory’s new Data Flow feature (limited preview) to build Slowly Changing Dimension (SCD) ETL patterns.
The Data Flow feature in ADF is currently in limited preview. If you would like to try this out on your Data Factories, please fill out this form to request whitelisting your Azure Subscription for ADF Data Flows: http://aka.ms/dataflowpreview. Once your subscription has been enabled, you will see “Data Factory V2 (with data flows)” as an option from the Azure Portal when creating Data Factories.
I’m going to start super-simple by building just the path in my data flow for an SCD Type 2 in the instance where the dimension member does not already exist in the target Azure SQL DW. In ADF Data Flow, you can have multiple paths in your data flows (called streams) that enable you to perform different data transformations on different data sources in a single Data Flow.
In this case, I will look-up from the DW to see if the incoming product already exists in the DW dimension table. If it does, I’ll branch off and update the row with the new attributes (I’ll blog that path later). For this blog, we’ll complete the path to create a new surrogate key for the row and clean up some of the attributes before loading the new row into the target DW dimension table.
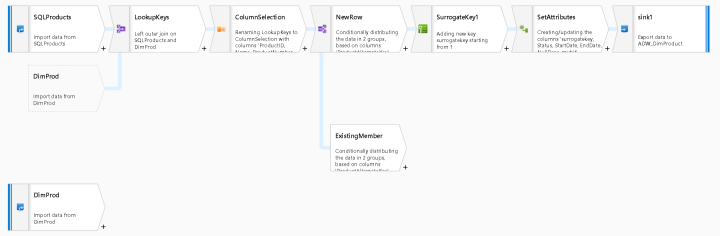
The first thing I’ll do is to add 2 sources, 1 for the Azure SQL OLTP dataset which has products that were sold today. The 2nd source is a query from the existing DW DimProducts table which has existing unique rows from the products dimension table. Because I am demonstrating a Type 2 SCD, the active dimension members can be signified with NULL as the End Date or ‘Y’ in the Status column to indicate that is the row to use in calculations. To use this query for the 2nd source at the bottom of the diagram, I created a SQL View with the proper query predicate and used the view as my source in the ADF Dataset. However, I could have also used Data Flow directly as the query predicate using the Filter transform and an expression of isNull(EndDate) or EndDate > addMonths(currentDate, 999), depending on the method that you choose to utilize for your SCD management in your dimension tables.
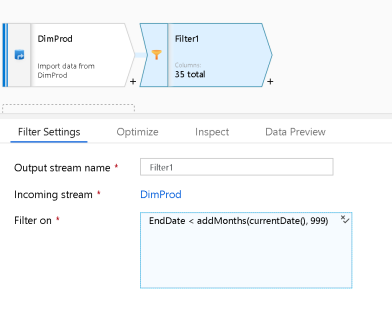
ADF Data Flow is smart enough to take your end-to-end flows and optimize the execution utilizing pushdown techniques when available. So, using a Filter transform against what appears like a complete table scan in the design view may not actually execute as such when you attach your Data Flow to a pipeline. It is best to experiment with different techniques and use the Monitoring in ADF to gather timings and partition counts on your Data Flow activity executions.
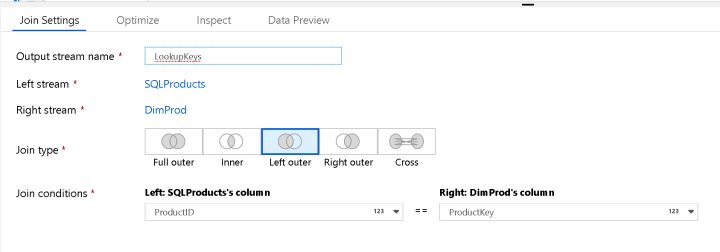
There are several different ways to proceed from here. In this demo, I used a Left Outer Join so that I can get all of the new products and all of the existing products in a single query, then I split the flow with a Conditional Split based on whether the surrogate key (stored in ProductAlternateKey) was set.
If the OLTP source has this value in this sample, then I can drop to the bottom stream in the Conditional Split. I did not yet build out this flow, but what I will do here is to look to see if the stored attributes in the DimProduct table are updated. If I make a determination that the dimension row requires a new row, then I’ll add that row to the DW in the bottom stream.
Using the Lookup transform within ADF Data Flow is also a very common mechanism to use to lookup reference values that can be leveraged in this case. You can utilize this pattern for SCD Type 2 when you want to match the DW member values incoming values to update the table when an attribute changes.
Real quick, I want to point out the Select transform immediately following my Join. This is an important concept in ADF Data Flow. All of your columns will automatically propagate throughout your streams. As your columns accumulate, you can use the Select transform to “select” the columns that you wish to keep. You will see stream names appended to the column names to indicate the origins and lineage of those columns to help you make the proper determination.
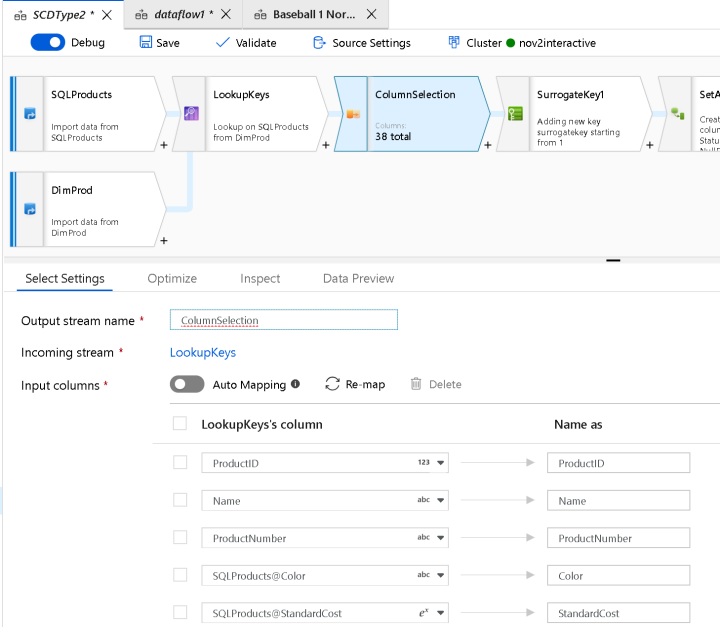
While you can always choose column selectivity in the Sink transform at the end of your Data Flow, maintaining column hygiene may help you to prune your column lists. The downside to this approach is that you will lose that metadata downstream and will not be able to access it once you’ve dropped it from your metadata with a Select.
Now, we need to add a surrogate key. Use the Surrogate Key transform to generate a unique key that will be stored, in this case, in ProductAlternateKey as a way to provide a key that is used for inner joins in the DW star schema and for our BI/analytical solutions. This is a key that is not a business key and is not part of the OLTP system. This is specific to the data warehouse in joining facts to dimensions.
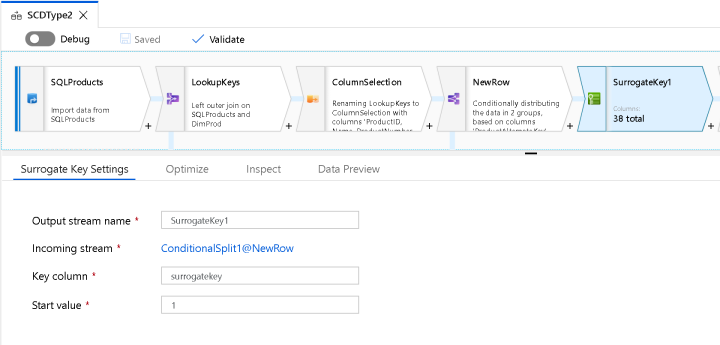
The ADF Data Flow surrogate transform will provide an incrementing value, so I’m going to prepend some text to the beginning of that value to demonstrate how to give your own flavor to the key. I decided to do this all in one Derived Column transform that I called “SetAttributes” below: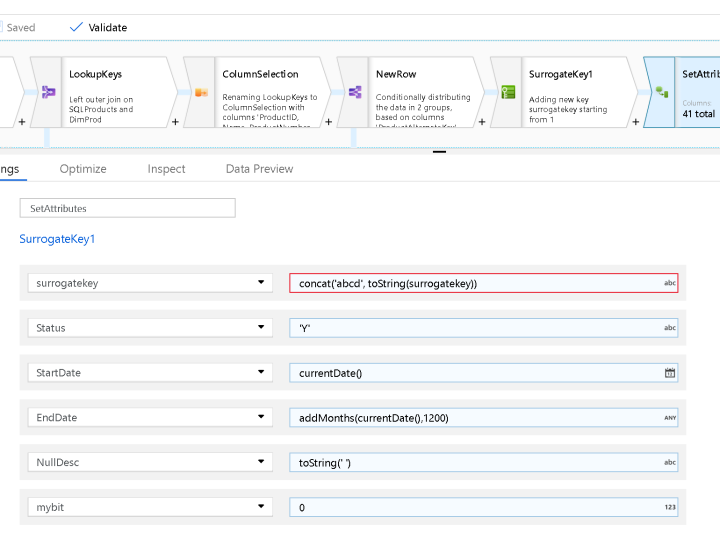
You can always create separate Derived Column transforms for these formulas, but I just found it easier to build all of my expressions in one transform for this sample.
The other formulas are setting up attributes that I’ll use to hold some stored data for publishing into the SQL DW DimProd table. I’m using ‘Y’ for active status of the dimension member, setting a StartDate for the row, EndDate in the future, empty strings instead of NULLs and setting a bit to use because my target schema requires it.
Now all you have to do is sink your fields in your Azure SQL DW with a Sink transform and you’re SCD Type 2 data flow will be complete. In order to execute this flow on a schedule, create a new ADF Pipeline and add a Data Flow activity that points to this SCD Data Flow. You’ll be able to use the full range of ADF schedules and monitoring to operationalize your data warehouse loading in ADF.

Is there an option we should use to enable this for an Azure account tied to a Developer subscription instead of directly to a company?
Yes, you can submit that request here: http://aka.ms/dataflowpreview
Thanks for your article. Does the surrogate key always start from one? If so I guess that means you need to select MAX from the dimension table at the start and add that to the surrogate key
Start Value is a configurable value in Surrogate Key, you can change it from the default of 1, or use the method you described and add a modifier to the value via Derived Column, both will work.
Excellent blog. I wonder if Data Flow has a transform that can update the sink with changed attribute values from the source, meaning how can Data Flow handle updates to the sink ?
It’s coming soon
Is this possible to update the sink with modified value as part of SCD Type 2 if sink type is csv.
If you have a CSV sink instead of a DB sink, then you will need to use the data lake CRUD update pattern. You’ll find an example under ADF pipeline templates. Note that the Alter Row won’t work without a database sink, so you need to read all the values in from the source file, then apply updates and deletes via Exists transformation.
Hi Curious, would you have any insight on when the Data Flows might be generally available? We would like to leverage Data flows but are hesitant to expend time and resources prior to being production ready.
Q4 CY19