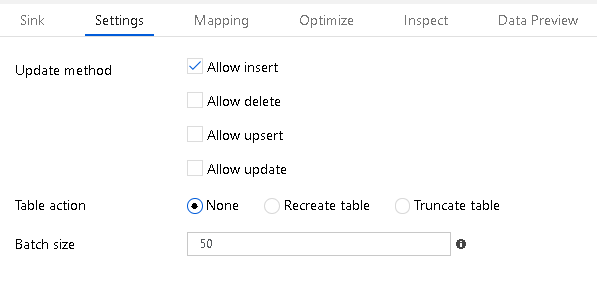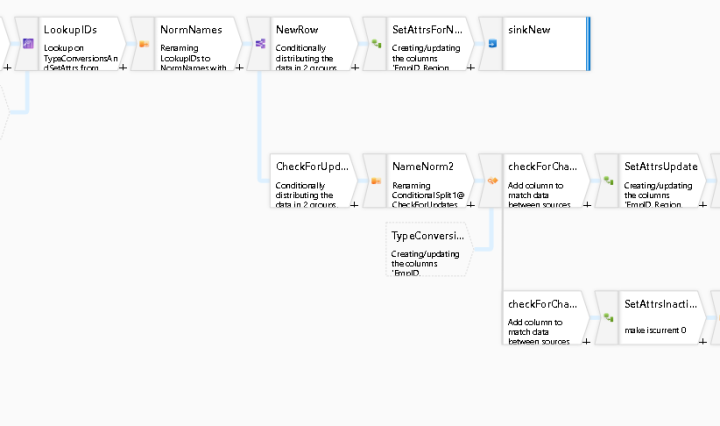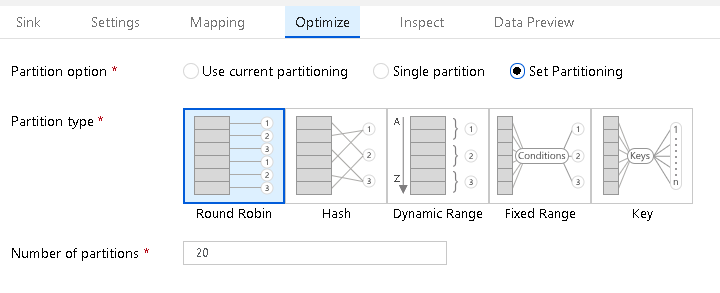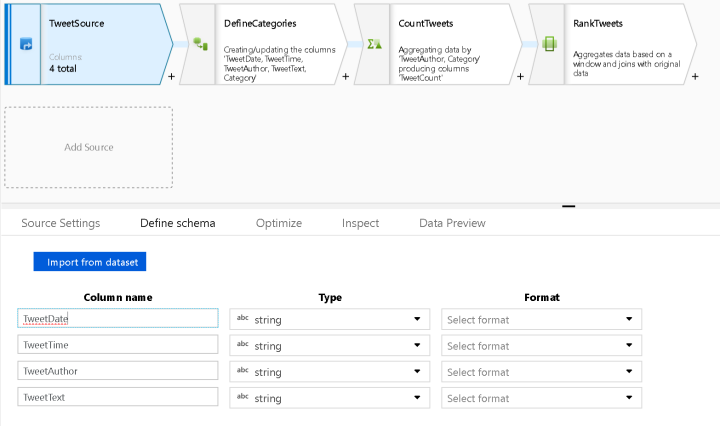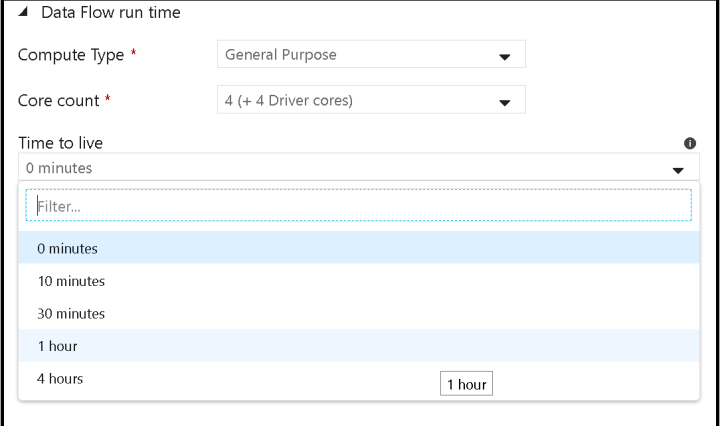
Reduce Execution Time for Data Flow Activities in ADF Pipelines
In ADF Mapping Data Flows, there are 2 working modes: Debug mode and Pipeline mode. Debug mode is active when you turn on the Data Flow debug switch and the light is green, showing debug as active. You will also … Continue reading Reduce Execution Time for Data Flow Activities in ADF Pipelines